
 When you scan a barcode how does the data in the barcode get translated into letters and numbers? The bars and spaces somehow represent letters and numbers. But how? Interestingly, different types of barcodes accomplish this in different ways.
When you scan a barcode how does the data in the barcode get translated into letters and numbers? The bars and spaces somehow represent letters and numbers. But how? Interestingly, different types of barcodes accomplish this in different ways.
UPC is about as simple as it gets. That is partly because it is a numeric-only barcode. Just 0 thorough 9. But even with the humble UPC, it is not quite as simple as that. Besides encoding numerical characters, there are other problems to solve. One problem is making sure the scanner decodes the string of numbers in the correct sequence. How does a scanner know the first number from the last, if it is scanned right side up or inverted? How can it distinguish left from right?
Some barcodes do this by using a start and stop pattern of bars and spaces that begin and end the symbol. UPC does it differently—and it is fascinating. UPC has start and stop bars too, but they are identical. Did you ever notice those two bars in the center of a UPC? They mark the center of the barcode. The start/stop bars and spaces do not identify left and right uniquely. It has to be done in a different way. Here is how.

The left half of a UPC/EAN symbol encodes numbers differently than the numbers on the right half. The pattern of bars and spaces for a 3 on the left side are different than for a 3 on the right side. This how a scanner can determine left from right and decode the UPC/EAN in the correct sequence. But there is something even more interesting about this symbol type.
A UPC contains 12 digits of data. You can see it with virtually every barcode—12 readable digits under the barcode, right? Well, not really. UPC encodes 13 digits of data.
Let’s take a closer look at basic structure for a moment. In review: each character in a UPC numbers is encoded in a pattern of 2 bars and 2 spaces. Two bars per character = 24 bars. The start and stop characters add 4 more bars—28. The center bar pattern adds two more bars. Total = 30 bars, 29 spaces.
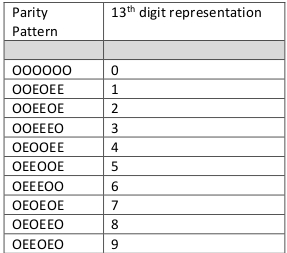
How could a UPC encode a 13th character without additional bars and spaces? It is very clever. We already know that left-side characters are different from right-side characters. We will call the left side characters L characters, and the ride-side characters R characters. What if there were two types of L characters? We will call them L-even and L-odd. An L-even number 1 would look different from an L-odd number one, although they are both number one. We will call that difference “parity”.
In the US, the left-side numbers of UPC symbols are all L-odd characters. The uniform parity pattern of all L-odd numbers actually represents a 13th digit, which is 0. This zero is technically present on all UPC numbers as a prefix. People are sometimes confused when the zero appears in some scanning systems, it that 13th digit has always been there.

Here is a chart showing how parity patterns of L characters represent the 13th number.
European Article Numbering (EAN) barcodes are a close cousin of the UPC and routinely encode 13 digits.
You can see the parity differences in left-side characters in the barcodes used on most books. This barcode is called Bookland EAN.

In this way, the limited data capacity of EAN/UPC increases without occupying any additional space. Ingenious!
![]() Comments and questions are always welcome. Contact us here.
Comments and questions are always welcome. Contact us here.


